HARKへのリンクはコチラ
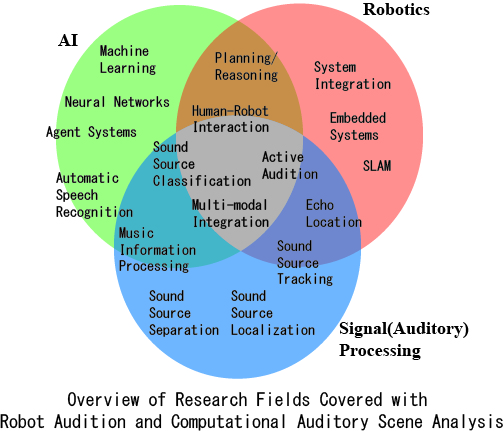
ロボット聴覚研究は,人工知能,信号処理,ロボティクスをまたがる新たな研究分野として 2000 年に提唱された比較的新しい研究分野です.
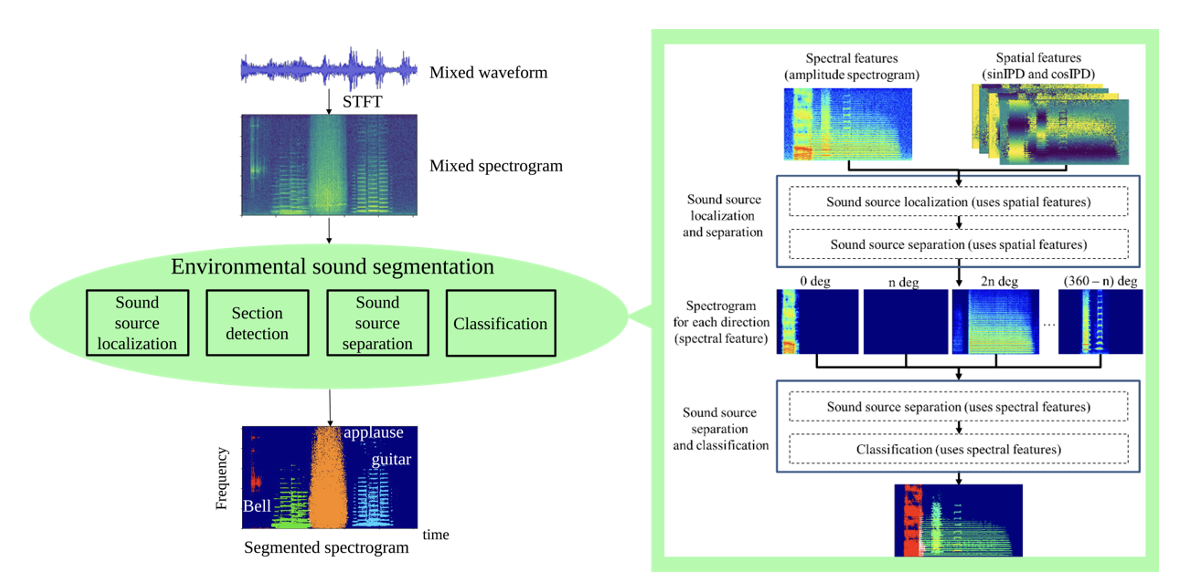
こうした問題に対し,ロボットならではの動作を積極的に利用するアクティブオーディションを鍵として,音源の位置推定(音源定位),目的音源の抽出(音源分離),抽出音源の認識(音声認識)といった要素技術を扱っています。これまで培ってきた技術は、ロボット聴覚のオープンソースソフトウェアHARK
HARKを用いれば,例えば,聖徳太子のように複数の人が同時に話してもそれぞれの人の声を聞き分ける技術が構築できます.このような技術は,人間が普段聞いている音は様々な音が混ざり合った混合音であることを考えると,実環境を扱う上で本質的な技術であるといえます。また、近年では、これらに加えて,可聴音による距離推定や,深層学習によりダメージを受けた音響信号を修復する技術,深層学習による音響信号の識別といった研究にも力を入れています。
ロボット(Willow Garage 社 Taxai)頭部に搭載したマイクアレイによる音源分離
VIDEO
HEARBO (HRI-JP)による 11人同時発話認識
VIDEO
音源の分離についても様々な側面から新しい手法の検討を行っている。
スポットビームフォーミング
マイクロホンアレイ処理による音源分離は方向情報を元に音源を分離するので,基本的に同じ方向に複数の音源の分離はできません。複数のマイクロホンアレイを組み合わせてこれを解決する手法の構築を行っています。また、この手法は複数のマイクロホンアレイを正確に同期する必要がないという利点も併せ持っています。
面音源の音源分離
音響信号処理の多くは,点音源を仮定しており,マイクロホンアレイ処理にもこれが当てはまります。屋外のコンサートで,周りの雑音から音楽だけを分離したり,逆に周りの雑音を分離しようとすると,面音源を前提にした処理が必要になります。この問題を解決するために,複数の点音源ビームフォーマを組み合わせることで高速に面音源を分離抽出する手法を提案しています。
定位・分離・識別の統合フレームワーク
ロボット聴覚や音環境理解では,定位,分離,識別といった処理がカスケード的に統合されることが多いが,そうした統合手法では,誤差が溜まってしまい最終的にエラーが大きくなるという問題があります。そこでこの問題を解決するため,深層学習を用いて,これらをend-to-endで統合した手法を提案しています。
使い勝手の良い informed 音源分離
音楽音響信号の分離では,楽譜情報など音響信号以外の情報が利用できるので,そうした情報を用いて分離性能を向上する研究が発表されている。しかし,こうした情報は,多くの場合,手動で準備する必要があるため,作成のコストが大きい。そこで、一部の音符の発音タイミングを入力するだけで分離性能を向上できる手法を提案しています。
移動ロボットのための単一マイクを用いた音源定位
正確な音源定位(音がどこから来ているかを特定すること)は、ロボットが周囲の空間状況を理解し、推論や意思決定を行うために重要です。